서브쿼리
- 서브 쿼리 뒤에는 반드시 별칭(alias)을 가져야 함
- SELECT 명령이 어떤 값을 반환하는 지 중요
SELECT 구에서 사용하기
SELECT (SELECT COUNT(*) FROM Sample51) AS sql1,
(SELECT COUNT(*) FROM Sample54) AS sql2;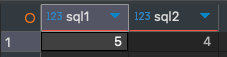
SET 구에서 서브쿼리 사용하기
- UPDATE 의 SET구에서도 사용 가능
# ERROR ver.
UPDATE Sample54 SET a=(SELECT MAX(a) FROM Sample54);
# Revised ver.
UPDATE Sample54 SET a=(SELECT max_val
FROM (SELECT MAX(a) AS max_val FROM Sample54) AS temp);
FROM 구에서 서브쿼리 사용하기
- SELECT 에서는 스칼라 서브쿼리를 써야했지만, FROM 에서는 그러지 않아도 무관❗️
- SELECT 문 안에 SELECT 가 들어가있는 것 처럼 보이므로, Nested 구조 (중첩구조, 내포구조) 라고도 부름
SELECT * FROM (SELECT * FROM Sample54) abc;
따라서 다시 한 번 복습해보자면...
- WHERE 구 : 스칼라값으로 자주 사용됨
- SET 구 : 다른 테이블의 데이터를 기반으로 업데이트할 때 자주 쓰임
- SELECT 구 : 전체 데이터셋과 각 행을 비교할 때 자주 쓰임
- FROM 구 : 복잡한 집계나 조인 결과를 임시 테이블처럼 사용할 때 자주 쓰임
직접 해보기
# Q1. 평균 곡 길이보다 긴 곡들의 이름과 길이를 조회 (WHERE 절에 서브쿼리)
SELECT Name, Milliseconds
FROM Track
WHERE Milliseconds > (SELECT AVG(Milliseconds) FROM Track)
ORDER BY Milliseconds;
# Q2. 각 장르별 평균 곡 길이(초 단위)를 조회 (FROM 절에 서브쿼리 사용)
SELECT *
FROM (SELECT GenreId, AVG(Milliseconds)/1000 AS AvDurSec
FROM Track GROUP BY GenreID) new;
# Q3. 모든 트랙의 이름, 길이, 평균 트랙 길이와의 차이를 조회 (SELECT 절의 연산에 스칼라 서브쿼리 사용)
SELECT Name, Milliseconds, Milliseconds - (SELECT AVG(Milliseconds)
FROM Track) AS Dur_AvgDur
FROM Track ORDER BY Dur_AvgDur;
상관 서브쿼리
- EXSITS 라는 술어로 조합하여 사용하는 서브쿼리 → 서브쿼리가 반환하는 결과값이 있는지를 조사할 수 있음
- Syntax
- [NOT] EXISTS (SELECT 명령)]
- 주로 정보 업데이트 시 활용
- 서브쿼리를 사용해 집합 간의 비교를 할 때 활용
UPDATE Sample551 SET a="있음" WHERE
EXISTS(SELECT * FROM Sample552 WHERE no2 = no);- NOT EXISTS 를 통해, 행이 존재하지 않는 경우에 참이 되게하는 것도 가능
UPDATE Sample551 SET a="없음" WHERE
NOT EXISTS(SELECT * FROM Sample552 WHERE no2 = no);- 상관 서브쿼리를 사용해, 다른 테이블의 상황을 판단하고 UPDATE 로 갱신 가능 (Excel 에서 Vlookup 과 비슷)
- SELECT, DELETE 명령으로도 서브쿼리 사용 가능
SELECT * FROM Sample551 WHERE
NOT EXISTS(SELECT * FROM Sample552 WHERE no2 = no);- 두개 이상의 테이블을 사용할 때는 열 이름 앞에, 테이블 이름을 붙여주는 것이 좋음 (열명이 같을 수도 있음)
SELECT * FROM Sample551 WHERE
NOT EXISTS(SELECT * FROM Sample552 WHERE Sample552.no2 = Sample551.no);
IN
- 보통 스칼라 값을 비교할 때는 "=" 연산자를 사용했음
- 집합을 비교할 때는 "IN" 을 사용해야함
- 집합 안의 값이 존재하는 지 조사 가능
- 서브쿼리를 사용할 때, IN 을 통해 비교하는 경우도 많음
- Syntax
- 열명 IN (집합)
- NOT IN 도 사용 가능
SELECT * FROM Sample551 WHERE no in (1, 3, 5);
SELECT * FROM Sample551 WHERE no in (SELECT no2 FROM Sample552);
SELECT * FROM Sample551 WHERE no NOT in (SELECT no2 FROM Sample552);- 집합 안에 NULL 값이 있어도 무시하지 않음 → 다만, NULL = NULL 은 제대로 계산 불가 → 즉, IN 을 사용해도 NULL 값 비교 불가
- NULL 비교 시, IS NULL 을 사용해야함
- NOT IN 의 경우, 집합 안에 NULL 이 있으면 참을 반환하지 않음 ( 그 결과는 UNKNOWN(불명)이 됨)
직접 해보기
# Q1. Invoice 테이블을 사용해 "USA" 에 있는 고객들의 주문 정보를 조회
# 각 고객별로 고객ID, 주문횟수, 총 주문금액을 표시하고, 총 주문 금액이 큰 순서대로 정렬
# WHERE 구에 IN 과 서브쿼리 사용
SELECT CustomerId, COUNT(InvoiceId), SUM(Total) FROM Invoice i
WHERE i.CustomerId IN
(SELECT c.CustomerId FROM Customer c WHERE Country = "USA")
GROUP BY CustomerId ORDER BY SUM(Total) DESC;
CTEs (Common Table Expressions)
- 임시 결과 집합을 선 정의하고, 그것을 쿼리 내에서 재사용하도록 도와주는 기능
- 가독성을 높이고, 복잡한 서브쿼리를 간결하게 표현하기 위해 사용
- Syntax
- WITH "테이블명" AS (Subquery) SELECT * FROM "테이블명"
WITH US_Customers AS (
SELECT
CustomerId,
FirstName,
LastName,
Country
FROM Customer
WHERE Country = 'USA'
)
SELECT
CustomerId,
FirstName,
LastName,
Country
FROM US_Customers
LIMIT 5;
지금까지 배운 내용이 포함된 코드이다. 한 줄씩 해석해보면 좋을 듯하다.
WITH CustomerPurchases AS (
SELECT
c.CustomerId,
SUM(i.Total) AS TotalPurchases
FROM customer c
JOIN Invoice i ON c.CustomerId = i.CustomerId
GROUP BY c.CustomerId
),
CustomerCategories AS (
SELECT
CustomerId,
TotalPurchases,
CASE
WHEN TotalPurchases > 40 THEN 'High Value'
WHEN TotalPurchases > 20 THEN 'Medium Value'
ELSE 'Low Value'
END AS CustomerCategory
FROM CustomerPurchases
)
SELECT
CustomerCategory,
COUNT(*) AS CustomerCount,
AVG(TotalPurchases) AS AveragePurchases
FROM CustomerCategories
GROUP BY CustomerCategory
ORDER BY AveragePurchases DESC;
쿼리사관학교
# Q1. track 테이블을 사용해 각 작곡가의 모든 트랙의 총 재생시간을 계산
# 총 재생시간이 2시간 이상인 작곡가만 조회
# 결과를 총 재생 시간이 긴 순서대로 정렬
SELECT Composer, SUM(Milliseconds)/3600000 AS TotalDurHour
FROM TRACK
WHERE Composer IS NOT NULL
GROUP BY Composer
HAVING TotalDurHour >= 2
ORDER BY TotalDurHour DESC;
복수의 테이블
- 복수의 테이블을 다루는 방법은 크게 두가지로 나뉨
- 합집합(Union) : 행이 추가되는 형식으로 아래에 연결됨
- 결합(Join) : 열이 추가되는 형식으로 옆으로 연결됨

UNION (합집합)
- 두 개 이상의 SELECT 명령을 하나로 연계해 질의 결과를 얻을 수 있음
- Syntax
- SELECT문 UNION[ALL] SELECT문 [ORDER BY 열명];
SELECT * FROM sample71_a
UNION
SELECT * FROM sample71_b;
SELECT * FROM sample71_a
UNION ALL
SELECT * FROM sample71_b;
- 여러개의 SELECT 명을 하나로 묶을 수 있음 → 다른 열을 갖고 있는 것을 합집합 시키고 싶을 때는, SELECT 문에 열명을 명시하면 가능
SELECT a FROM Sample71_a
UNION
SELECT b FROM Sample71_b
UNION
SELECT age FROM Sample31;
- SELECT 문의 순서가 바뀌면, ORDER BY 를 지정하지 않았을 때, 결과값 데이터의 순서가 바뀔 수 있음
- UNION 에서 ORDER BY 를 사용한다면, 마지막 SELECT 문에만 지정하도록 하자.
- 합치는 열의 이름이 다를수도 있기 때문에, 별명을 붙이는 것이 일반적
- 기본적으로 DISTINCT 로 중복 제거된 뒤 출력 → UNION ALL 을 사용하여, 중복을 포함할 수 있음
SELECT a AS c FROM sample71_a
UNION ALL
SELECT b AS c FROM sample71_b
ORDER BY c;
JOIN (결합)
- 테이블 결합은 RDBMS 에서 대단히 중요한 개념
- 보통 데이터베이스는 하나의 테이블에 많은 데이터를 저장하지 않고, 여러 개의 테이블에 나눠서 저장
- 여러 개로 나뉜 데이터를 하나로 묶어서 결과를 내는 방법을 테이블 결합이라고 함
- JOIN 종류
- INNER JOIN (내부 결합)
- OUTER JOIN(외부 결합)
- Syntax
- SELECT * FROM table1 INNER(OUTER) JOIN table2 ON 결합조건
- Syntax
INNER JOIN
- 테이블 두개에서 서로 중복되는 값만 출력
SELECT i.상품명, m.메이커명
FROM item2 i
INNER JOIN maker m ON i.메이커코드 = m.메이커코드;- 세 개 이상의 테이블 결합도 가능
SELECT
c.LastName,
c.FirstName,
t.Name AS TrackName,
a.Title AS AlbumTitle
FROM
Customer c
INNER JOIN Invoice i ON c.CustomerId = i.CustomerId
INNER JOIN InvoiceLine il ON i.InvoiceId = il.InvoiceId
INNER JOIN Track t ON il.TrackId = t.TrackId
INNER JOIN Album a ON t.AlbumId = a.AlbumId
ORDER BY
c.LastName, c.FirstName;
직접 해보기
# Q1. 각 album 의 제목과 해당 앨범을 작곡한 아티스트의 이름을 조회
SELECT a.Title, ar.Name
FROM Artist ar
INNER JOIN Album a ON a.ArtistId = ar.ArtistId;
# Q2. 각 장르별로 트랙의 수와 총 재생시간을 조회
SELECT g.Name, COUNT(t.TrackId) TotalTrack, SUM(t.Milliseconds) TotalDuration
FROM Track t
INNER JOIN Genre g ON g.GenreId = t.GenreId
GROUP BY g.Name;
# Q3. 고객의 이름과 그들이 주문한 총 금액을 조회
SELECT i.CustomerId, c.FirstName, c.LastName, SUM(i.Total) AS TotalAmount
FROM Invoice i
INNER JOIN Customer c ON c.CustomerId = i.CustomerId
GROUP BY i.CustomerId, c.FirstName,c.LastName
ORDER BY TotalAmount DESC;
OUTER JOIN
- LEFT JOIN & RIGHT JOIN : 한 쪽 테이블에서는 모든 행을, 다른 쪽에서는 일치되는 행만 반환
- Syntax
- SELECT * FROM table1 LEFT JOIN table2 ON 결합조건

LEFT JOIN
- 왼쪽 테이블에서는 모든 행을 반환, 오른쪽 테이블에서는 일치하는 행만 반환
- 왼쪽 테이블과 일치하는 행이 없으면 NULL 값을 반환
상품 테이블과 재고 테이블을 LEFT JOIN 하여, 상품 별 재고수를 파악해볼 수 있다.
SELECT i.상품명, s.재고수
FROM item3 i
LEFT JOIN stock s ON i.상품코드 = s.상품코드;
WHERE 문을 사용해, 상품분류가 식료품인 것만 가져오는 것도 가능하다.
SELECT i.상품명, s.재고수
FROM item3 i
LEFT JOIN stock s ON i.상품코드 = s.상품코드
WHERE i.상품분류 = '식료품';
FULL OUTER JOIN
- 양쪽 테이블에서 모드 행을 반환하게 되고, 일치하는 행이 없으면 NULL 값을 반환
- Syntax
- SELECT * FROM table1 LEFT JOIN table2 UNION SELECT * FROM table1 RIGHT JOIN table2
SELECT * FROM item3 i
LEFT JOIN stock s ON i.상품코드 = s.상품코드
UNION
SELECT * FROM item3 i
RIGHT JOIN stock s ON i.상품코드 = s.상품코드;


직접 해보기
# Q1. 모든 고객의 이름과 그들의 담당 직원의 이름을 조회
# 담당 직원이 없는 고객도 결과에 포함되어야 함
# 결과는 고객의 성과 이름 순으로 정렬
SELECT c.LastName CustLastName, c.FirstName CustFirstName,
e.LastName EmpLastName, e.FirstName EmpFirstName
FROM Customer c
LEFT JOIN Employee e ON c.SupportRepId = e.EmployeeId;
# Q2. 모든 아티스트의 이름과 그들의 앨범 수,
# 그리고 가장 최근 앨범의 제목을 조회
# 앨범이 없는 아티스트도 결과에 포함되어야 함
# 결과는 앨범 수가 많은 순서대로 정렬, 앨범 수가 같다면 아티스트 이름 순으로 정렬
SELECT
a.Name, COUNT(al.AlbumId) TotalAlbum,
(SELECT Title
FROM Album al2
WHERE al.ArtistId = al2.ArtistId
ORDER BY al2.AlbumId DESC
LIMIT 1
) AS RecentAlbum
FROM Artist a
LEFT JOIN Album al ON a.ArtistId = al.ArtistId
GROUP BY a.ArtistId, a.Name
ORDER BY TotalAlbum DESC, a.Name ASC;
Reflection
초반에는 호기롭게 여겼던 sql... 서브쿼리와 조인으로 들어가면서 난이도가 급상승하면서, 또 다시 뇌의 과부화를 느꼈다. 괴롭지만, 그만큼 새로운 개념을 뇌에 적응 시키는 과정이라며 긍정적으로 되뇌인다. 직관적이라 느껴졌지만, 서브쿼리와 조인은 논외다. 결과를 떠올리며 역발상을 해주어야 한다. 따라서, 어떤 결과를 얻고 싶은 건지를 먼저 떠올리고, 그 다음 필요한 것이 뭔지 거꾸로 사고하는 방식의 훈련이 필요하다. 이는 파이썬과 마찬가지로 반복 쿼리 작성을 통해 체득되어야 하는 부분이다. 일단 오늘은 쿼리사관학교 코딩 문제풀이로 마무리 지어보려 한다..💪