날짜 연산 _ CURRENT_TIMESTAMP & DATEDIFF
- 날짜는 Date, 시간은 Time, 날짜와 시간은 Datetime 형으로 세분화 가능
- 날짜나 시간 데이터는 사칙 연산 가능
- Syntax
- SELECT CURRENT_TIMESTAMP; → 시스템 날짜를 출력하기 때문에 FROM 생략 가능
덧셈과 뺄셈 연산
- Syntax (덧셈)
- SELECT CURRENT_DATE + INTERVAL 숫자 DAY;
- SELECT ADD_DATE(NOW(), INTERVAL 1 DAY)
- 다양한 연산도 가능
SELECT DATE_ADD(NOW(), INTERVAL 1 SECOND);
SELECT DATE_ADD(NOW(), INTERVAL 1 MINUTE);
SELECT DATE_ADD(NOW(), INTERVAL 1 HOUR);
SELECT DATE_ADD(NOW(), INTERVAL 1 DAY);
SELECT DATE_ADD(NOW(), INTERVAL 1 MONTH);
SELECT DATE_ADD(NOW(), INTERVAL 1 YEAR);
SELECT DATE_ADD(NOW(), INTERVAL -1 YEAR);
- Syntax (뺄셈)
- DATEDIFF('날짜1', '날짜2')
SELECT DATEDIFF('2024-07-08', '2024-07-09');
❗️ 다른 연산들처럼, WHERE 문에서도 사용 가능
SELECT LastName, HireDate, DATEDIFF(HireDate, now()) FROM employee e
WHERE DATEDIFF(HireDate, NOW()) >= -8000;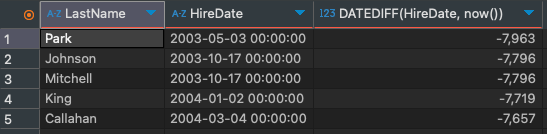
CASE 문으로 데이터 변환하기
- 파이썬에서 IF문이라고 할 수 있음

- WHEN 절에는 참과 거짓을 반환하는 조건식을 기술
- 해당 조건을 만족하여 참이 되는 경우, THEN 절에 기술한 식이 처리됨
- 어떤 조건식도 만족하지 못한 경우 ELSE 절에 기술한 식이 채택
- ELSE 를 생략한 경우, 'ELSE NULL' 로 간주
아래와 같이 두가지 옵션으로 쿼리를 작성해볼 수 있고, 출력값은 같다. 아무래도 두번째 옵션이 좀 더 간결하고 쉽게 느껴진다.
Opt 1.
SELECT a,
CASE
WHEN a=1 THEN '남자'
WHEN a=2 THEN '여자'
ELSE '미지정'
END AS "a(null=0)"
FROM sample37;
Opt 2.
SELECT a,
CASE a
WHEN 1 THEN '남자'
WHEN 2 THEN '여자'
ELSE '미지정'
END AS "a(null=0)"
FROM sample37;
❗️ CASE 문 주의사항
- CASE 문은 WHERE 이나 ORDER BY 구에서도 사용 가능
- ELSE 를 생략하면 ELSE NULL 이 되는 것에 주의 (생략하지 않는 편이 나음)
- WHEN 에서 NULL 을 사용할 경우 'IS NULL' 를 사용해야함
직접 해보기
# Q1. Invoice 테이블을 사용해 각 주문의 InvoiceDate 기준으로 분류하여 InvoiceID, InvoiceDate, 주문연도를 출력
# 2007년 데이터, 2009년 데이터, 2009년 이후 데이터로 분
SELECT * FROM Invoice;
SELECT InvoiceID, InvoiceDate,
CASE
WHEN InvoiceDate < '2009-01-01' THEN '2009년 이전 데이터'
WHEN InvoiceDate >= '2009-01-01' AND InvoiceDate < '2010-01-01' THEN '2009년'
WHEN InvoiceDate >= '2010-01-01' AND InvoiceDate < '2011-01-01' THEN '2010년'
WHEN InvoiceDate >= '2011-01-01' AND InvoiceDate < '2012-01-01' THEN '2011년'
ELSE '2011년 이후'
END AS '주문연도'
FROM Invoice;
# Q2. Invoice 테이블을 사용해 각 주문의 InvoiceDate 로부터 2011-12-31까지의 경과일을 계산하고, 경과기간을 분류
# ex. 1년 이내, 2년 이내, 3년 이내
SELECT InvoiceID, InvoiceDate, DATEDIFF(InvoiceDate, "2011-12-31"),
CASE
WHEN DATEDIFF(InvoiceDate, "2011-12-31") < 0 THEN "2012년 이전"
WHEN DATEDIFF(InvoiceDate, "2011-12-31") < 30 THEN "1개월 이내"
WHEN DATEDIFF(InvoiceDate, "2011-12-31") < 365 THEN "1년 이내"
WHEN DATEDIFF(InvoiceDate, "2011-12-31") < 730 THEN "2년 이내"
END "경과기간"
FROM invoice ORDER BY 경과기간;

데이터 추가, 수정, 삭제
INSERT _ 행 추가
- Syntax
- INSERT INTO 테이블명 VALUES (값1, 값2, ...)
- INSERT 를 통해 추가하려면 각 열의 값을 지정해야함 → 각 열에 어떤 유형의 데이터를 저장할 수 있는지 DESC 명력으로 확인해야 함
- NOT NULL 제약이 걸려있는 경우, null 값을 넣을 수 없음
DESC sample41;
- 확인 후, INSERT 문을 통해 데이터 추가
INSERT INTO sample41
VALUES (1, 'abc', '2024-07-08');
- 추가된 행을 확인 할 수 있음
SELECT * FROM SAMPLE41;
DELETE _ 행 삭제
- Syntax
- DELETE FROM 테이블명 WHERE 조건식
- 삭제는 신중해야함 → WHERE 문을 통해 조건을 지정하지 않으면, 모든 데이터 삭제됨
- 조건에 맞는 행이 없다면, 아무 일도 일어나지 않음
DELETE FROM sample41 WHERE no = 1;
- no = 1 조건식에 해당하는 행이 삭제 된 것을 확인 할 수 있음
SELECT * FROM sample41;
UPDATE _ 셀 수정(갱신)
- Syntax
- UPDATE 테이블명 SET 열1=값1, 열2=값2, ... WHERE 조건식
- UPDATE의 SET에서 사용하는 '=' 는 대입 연산자 (비교 연산자 아님!)
- 값들은 항상 '상수'로 표기해야함
- WHERE 문을 사용하지 않으면 모든 '행'이 갱신됨
- ,(콤마)로 구분하여 복수 열을 갱신할 수 있음
# 갱신1
UPDATE sample41 SET a = 'xyz'
WHERE no = 2;
# 갱신2
UPDATE sample41 SET a='xyz', b='2024-08-16'
WHERE no = 2;


- 셀의 값을 NULL로도 갱신 가능
UPDATE sample41 SET a=NULL
WHERE no = 2;
❗️ SELECT 와는 다르게 INSERT, DELETE, UPDATE 는 실제 데이터에 영향을 끼치므로, 주의해서 사용하기
직접 해보기
## Q1. Employee 테이블에서 전화번호가 +로 시작하지 않는 직원의 전화번호를 +1 로 시작하도록 변경
# opt1.
UPDATE Employee SET Phone = CONCAT("+", Fax)
WHERE NOT Fax LIKE "+1%";
# op2.
UPDATE Employee SET Phone =
CASE
WHEN Phone NOT LIKE "+1%" THEN CONCAT("+", Phone)
ELSE Phone
END;
## Q2. 새로운 직원을 Employee 테이블에 추가
INSERT INTO Employee(EmployeeId, LastName, FirstName)
VALUES (9, 'John', 'Doe');
## Q3. 방금 추가한 직원 John Doe 의 Title 을 Data Anlyst 로 변
UPDATE Employee SET Title = 'Data Analyst'
WHERE EmployeeID = 9;
집계와 서브쿼리
집계함수
- 대표적인 집계 함수
- COUNT
- SUM
- AVG
- MIN
- MAX
COUNT _ 행의 개수 집계
- SELECT 구는 WHERE 구보다 나중에 내부적으로 처리됨 → WHERE 구로 조건을 지정하면, 검색된 행이 COUNT 함수로 넘겨져서 집계함
SELECT * FROM Sample51;
SELECT COUNT(*) FROM Sample51;
SELECT COUNT(*) FROM Sample51 WHERE name='A';


- COUNT 의 인수로 * 대신 열 명을 지정할 수도 있음 → 보통 열의 개수를 구하기 위해서 사용
- NULL 값을 어떻게 취급하는지 상당히 중요 ! → COUNT 함수에서는 NULL 값을 무시
- 다만 COUNT(*) 의 경우는 모든 행수를 카운트하기 때문에 무시되지 않음
SELECT COUNT(no), COUNT(name) FROM Sample51;
- DISTINCT 로 중복을 제거하고 개수를 구하는 것도 가능
- Syntax
- SELECT COUNT (DISTINCT 열명) FROM 테이블명
SELECT COUNT(all name), COUNT(DISTINCT name) FROM Sample51;
SUM _ 행의 합 집계
- Syntax
- SUM([ALL|DISTINCT]집합)
- COUNT 와 마찬가지로 NULL 값 무시
SELECT SUM(quantity) FROM Sample51;
❗️SUM 을 비롯해 AVG, MIN, MAX 함수도 같은 용도로 쓰이는데, "수치형" 데이터만 연상 가능함을 유의
- Sample51 테이블에서 quantity 의 평균, 최솟값, 최대값 구하기
SELECT AVG(quantity), SUM(quantity)/COUNT(quantity),
MIN(quantity), MAX(quantity) FROM Sample51;
직접 해보기
# Q. track 테이블을 사용해 다음 정보를 조회하는 쿼리를 작성
# 전체 트랙수, 전체 트랙 총 재생시간(밀리초), 평균 트랙 길이(초),
# 가장 짧은 트랙 길이(초), 모든 트랙의 용량(분), 모든 트랙 용량, 평균 트랙 용량
SELECT * FROM Track;
SELECT COUNT(*) AS TotalTrack,
SUM(Milliseconds) AS TotalDurationMs,
AVG(Milliseconds)/1000 AS AvgTrackLengthSeconds,
MIN(Milliseconds)/1000 AS MinTrackLengthSeconds,
MAX(Milliseconds)/60000 AS MaxTrackLengthMinutes,
SUM(Bytes) AS TotalTrackBytes,
AVG(Bytes) AS AvgTrackBytes
FROM Track;
Group By _ 그룹화
- 그룹화를 통해 집계함수의 활용범위 넓히기 가능
- Syntax
- SELECT * FROM 테이블명 GROUP BY 열1, 열2, ...
SELECT name FROM Sample51 GROUP BY name;
SELECT name, COUNT(name), SUM(quantity) FROM Sample51 GROUP BY name;


- 집계함수는 WHERE 구의 조건식을 사용할 수 없음
- 내부 처리 순서
- WHERE → GROUP BY → SELECT → ORDER BY
- HAVING 구를 사용해 집계함수에서의 조건식을 지정 가능
- Syntax
- SELECT 열명 FROM 테이블명 GROUP BY 열명 HAVING 조건식
- 내부처리순서
- WHERE → GROUP BY → HAVING → SELECT → ORDER BY
- HAVING 에서는 별명을 사용 불가 !
- Syntax
❗️주의할 점 : GROUP BY 에 지정한 열 외의 열은 집계함수를 사용하지 않은 채 SELECT 에 기술해서는 안됨
SELECT no, name, quantity FROM Sample51 GROUP BY name;

- GROUP BY 구를 통해 그룹화한 경우에도, ORDER BY 구를 통해 정렬할 수 있음
SELECT name, COUNT(name), SUM(quantity) FROM Sample51
GROUP BY name ORDER BY SUM(quantity) DESC;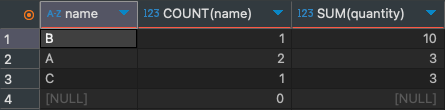
직접 해보기
# Q. Track 테이블을 사용하여 다음 정보를 조회하는 쿼리를 작성
# 각 아티스트의 이름, 트랙의 수, 트랙들의 총 재생 시간(분), 트랙의 총 가격 조회
# 트랙 수가 5개 이상 & 총 재생 시간이 30분을 초과하는 아티스트만 조회
# 결과를 트랙 수가 많은 순서대로 정렬
SELECT * FROM Track;
SELECT Composer,
COUNT(TrackId) AS TotalTrack,
SUM(Milliseconds)/60000 AS TotalTrackLengthMinutes,
SUM(UnitPrice) AS TotalAmount
FROM Track t
GROUP BY Composer
HAVING TotalTrack >= 5 AND TotalTrackLengthMinutes > 30
ORDER BY TotalTrack DESC;
서브쿼리
- SELECT 명령에 의한 데이터 질의로, 상부가 아닌 하부의 부수적인 질문을 의미
- 보통 다른 쿼리 내부에 포함되어 있는 SELECT 문을 의미
- Syntax
- (SELECT 명령)
- WHERE 구 : 스칼라값으로 자주 사용됨
- SET 구 : 다른 테이블의 데이터를 기반으로 업데이트할 때 자주 쓰임
- SELECT 구 : 전체 데이터셋과 각 행을 비교할 때 자주 쓰임
- FROM 구 : 복잡한 집계나 조인 결과를 임시 테이블처럼 사용할 때 자주 쓰임
Reflection
3일차에 벌써 집계 및 그룹화까지 할 수 있게 되었다. (+일부 서브쿼리 맛보기..) 마음 먹고 달려들면 안되는 게 없구나.. 확실히 파이썬 보다 언어가 직관적이라 학습하기가 더 수월했던 것도 있었다. 다만, 앞으로 쿼리 작성을 할 때, 한 줄 작성 후 실행을 반복하며 실시간으로 잘 출력되고 있는지에 관한 현황을 파악해가며 사전에 오류를 방지할 수 있도록 해야겠다. 프로젝트를 진행하게 될 때, sql 이 어떤 방식으로 활용될 지는 아직 잘 그려지지는 않는다. 전처리 과정에 유용하게 쓰일 것이라는 감만 가지고 있다. 따라서, 다른 분들의 프로젝트 사례를 조금 더 서치해봐야 할 것 같다. 벌써 다음주가 프로젝트 시작이다.. 일단 이번주까지는 ADSP 자격 시험에 집중을 한 후 주말동안 서치를 해보도록 하자..💪