[성동3기 전Z전능 데이터 분석가] DAY 12 _ 데이터 분석 기획 기초 실습
오전
데이터 분석 특강
데이터 분석의 쓰임
데이터 분석의 쓰임이 뭘까? '가장 효율적인 의사소통 수단' 으로써 데이터 분석은 의미를 가진다.

데이터분석이 필요한 3가지 예시(시나리오)는 아래와 같다. 데이터 분석가가 현업에서 일반적으로 자주 마주하게 되는 상황이라고 한다.
1) 어떤 지역에 카페를 차리지? 대학생 타겟으로 창업하면 성공할까?
- 목표 : '지역별 대학생 거주인구 수'와 '지역별 카페의 1년 내 생존률' 두 변수 간의 상관관계 분석
- 가설 : '지역별 대학생 거주 인구수'와 '지역별 카페의 1년 내 생존률' 은 상관관계가 없다.
2) 영어 교육 앱을 운영 중인 B업체는 최근 B2B 계약을 앞두고 있다. 고객사에서 앱의 교육 효과를 증명해달라 했고, B업체는 사용자들이 앱을 사용하기 이전과 이후의 토익 점수가 실제로 차이가 있는지를 통계적으로 검증하고 싶다.
3) 모바일 게임 회사 전략팀에 근무하는 C씨는 지난해에 비해 올해 매출이 줄어들었다는 사실을 깨닫고 원인을 분석해보고 싶다.
- 목표 : 모바일 게임의 매출 저하 원인 발굴
- 방법 : 추정 논리 수립(MECE, 로직트리, 페르미추정) - 데이터 수집 - 계산
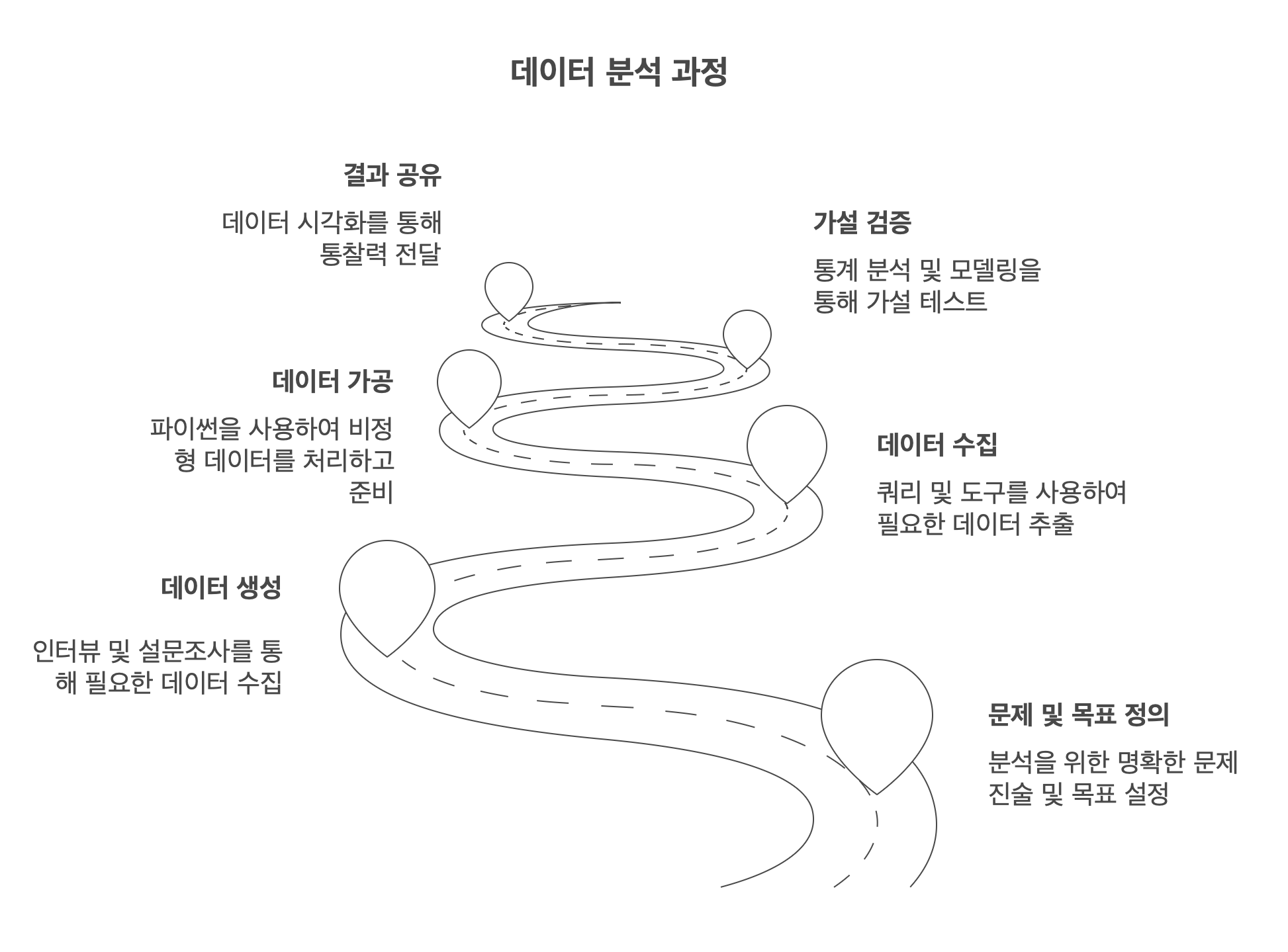
데이터 분석 과정
데이터 분석을 하기 전 각 단계의 과정을 인지할 필요가 있다. 프로세스는 대략 아래와 같다.
데이터로 일하는 조직이 되기 위해 필요한 것
데이터로 일하기 위해서는 두가지가 필요하다. 하나는 데이터 분석을 위한 인프라, 다른 하나는 데이터리터러시이다. 특히나 데이터로 일하는 문화가 정착되지 않은 환경이라면 리터러시를 높이기 위한 작업부터 시도해야 한다.

데이터 리터러시
- 조직이 데이터로 일할 수 있는 문화와 역량을 갖추고 있어야 함 (특히 리더십)
- 높은 수준의 데이터분석을 모두가 갖추는게 아닌, 아이디어에 대해 데이터로 논의 하는 문화가 필요
- 리터러시가 낮은 조직이라면? 데이터 수집, 가시화에 집중. 눈에 보이면 관리에 대한 니즈가 생김
데이터 직군
데이터 직군은 과거로부터 인프라가 구축되며 점진적으로 변화되어 왔다.

직군, 기업에 따른 데이터 업무 환경
기업에 따라 데이터 분석가가 하는 일이 꽤나 차이가 있다. 크게 2가지로 나뉠 수 있는데, 하나는 데이터를 만드는 데에 시간을 많이 들이는 회사, 그리고 쌓인 데이터를 찾는데에 시간을 많이 들이는 회사이다.
또한 본인이 속한 팀이 데이터 전문 부서인지 아닌지에 따라 필요한 역량과 하는 업무가 꽤 차이가 난다.
데이터분석가의 커리어
분석가는 다양한 직무와 맞닿아 있다. 그렇기 때문에 경력이 쌓이면서 자연스럽게 직무를 바꾸기도 한다.

데이터 분석 실습 - 논리적 사고 훈련
첫번째 데이터 분석 실습으로 '논리적 사고 훈련' 을 실시했다. 대표적인 논리적 사고 방법론으로 '페르미 추정' 이 있다. '부분을 보며 전체의 그림을 상상하는 방식' 으로 진행된다.
아래는 '시카고에 피아노 조율사가 몇명일까?' 연간 조율 건수 예측하기에 대한 페르미 추정 과정 예시이다.

이와 같은 방식으로, '장한평역 내 컴포즈 카페의 연 매출은 얼마일까?' 라는 주제를 가지고 페르미 기법을 활용해 연 매출을 추정해보았다.

오후
인과관계
데이터 분석을 통해 다양한 인사이트를 얻을 수 있다. 예를 들어, 매체 분석을 통해 어떤 채널로 광고를 송출할지 선택, 비용 대비 최대 효율을 내는 광고를 기획, AB테스트 기반 고객의 전환율을 높이는 UI설계, 수요예측을 기반으로 확보할 재고량 계산, 관리 등이 있다.

구체적인 사례로 매체를 선택할 때, 데이터 분석을 사용할 수 있다. '어떤 채널을 통해 광고를 송출해야 비용 대비 효과가 클까?'
무신사에서 지난 9월부터 디지털 광고 송출량을 늘리자 매출이 늘었다. 그러니, '디지털 광고의 효율이 좋으니 오프라인 광고 지출을 줄이고 디지털 광고 지출을 늘리자?'
명확한 인과성을 지녔다 할 수 있을까? 혹은 FW시즌 교체기가 되면서 매출이 늘어난 것 일지도 모른다.
프로덕트 UI/UX를 설계할 때에도, 데이터 분석을 사용할 수 있다. '제품의 컴포넌트를 어떻게 설계해야 고객이 우리가 원하는 액션을 취할까?'
커머스에서, 집단을 나눠 한 집단에는 필터가 없이 최저가 순으로 제품을 나열하고, 다른 집단에선 여러 필터를 적용해 선택 가능하게 했더니 필터가 없을 때 구매율이 높았다. 그러니, '필터를 없애자?' 필터와 구매율 간 명확한 인과성을 지녔다고 볼 수 있을까?
필터가 없는 집단은 실험 전부터 구매빈도가 월 3회, 필터가 있는 집단은 월 2.1회로 원래 필터 없는 집단이 구매를 많이 했던 거라면, 실험 집단 특성이 동질하지 못했기 때문에, 인과성에 대한 신뢰도는 낮아지게 된다.
재고 관리를 할 때, 데이터 분석을 사용할 수 있다. '올해 영업 중 재고가 부족한 경우를 방지하기 위해 몇개의 재고를 확보해놓아야할까?'
고급 가구를 판매하는 회사에서 3년 전의 제품 판매량이 8만개, 제작년의 제품 판매량이 10만, 작년의 제품 매출이 12만개이다. 그러니, '올해는 14만개의 제품이 팔릴 것이니 미리 재고를 준비하자?' 가 명백한 인과성에 따른 것인가?
제품을 구매할 수 있는 고객은 이미 대부분 구매를 마쳐 이제 판매량이 감소할 시기일 경우, 14만개가 아니라 매출이 더 하락할 수도 있는 것이다.
위 3가지 사례를 통해 공통적으로 알 수 있는 것은, 분석으로 잘못된 인과관계가 나오면 오히려 역효과가 날 수 있다는 것이다.
인과관계 파악의 원리
인과관계를 알기 위해서는 두가지 시나리오를 둘 다 시뮬레이션 해보는 것으로 알 수 있다. 어떤 자극(impact)으로 인해 만들어지는 효과를 우리는 개입효과(처치효과)라고 부른다.
인과관계를 아는 데에 있어서 근본적인 문제는 두 가지 다른 상황의 결과를 알지 못한다는 것이다. 대부분의 경우 우리는 하나만 선택할 수 있다.
일단 하나를 선택한 후 다른 선택도 실험해보면 되지 않을까? 싶지만 사실 시간이 흐르면서 많은 변수들이 생긴다. 이 변수들로 인해 이전의 실험 결과와 동일한 결과가 나올 것이라 확신할 수 없다. 인과추론을 위한 방법론들은 이런 한계를 극복하기 위한 아이디어들이다.
인과추론 방법론
'랜덤' 활용
광고 시청 여부가 아이스크림을 먹는양에 영향을 주는지 확신할 수 없는 이유는, 광고 시청 여부 외에도 많은 변수들이 아이스크림 먹는양에 영향을 미칠 수 있기 때문이다. 조금 더 확신을 얻기 위해서는, 광고 시청 외의 다른 변수는 완전히 동일한 채 비교가 되면 더 신뢰가 간다.
모든 변수를 동일하게 맞춘 1:1 비교는 어려우니, 사람을 많이(충~분히 많이) 모아놓고 랜덤하게 나눠 두 집단이 광고를 시청했는지, 안시청했는지 여부만 구분되게 한다. 흔히 데이터분석가들이 많이 수행하는 AB테스트 또한 RCT의 일종이다. 이 때, AB테스트를 위해서는 집단을 무작위로 잘 나누는 것이 중요하다.

인과 추론 실습
어떤 원인과 결과 관계를 분석할 때, 이 두 사이의 관계가 정말 인과관계가 맞을지 점검이 필요하다. 또한 데이터로 보인 관계 사이에는 다양한 변수가 영향을 미치고 있을 수 있다. 인과관계를 파악하기 위해선 여러 변수를 고려해 원인과 결과에 영향을 주는지 여부를 체크하고, 인과 관계를 교란시키는 요인은 제거해야 한다.
'캐치테이블의 예약금을 환불 불가로 할 때 예약 취소가 감소할 지 실험을 해보고 싶다. 어떤 변수들이 영향을 교란을 만들어낼까?'
아래와 같이 팀원과 함께 아이데이션을 해봤다. 먼저 '예약 취소' 에 영향을 줄 만한 변수들을 무작위 나열 후, grouping 하였고 실험 설계 시 데이터를 어떻게 수집할 수 있을 지, 데이터 수집 방법에 대해서도 논의해보았다.

통계적 유의성
유의성 검정의 원리
큰 수의 법칙이란 "어떤 일을 여러번 반복 하면, 혹은 어떤 것을 많이 모으면, 결국 평균적으로 예상했던 결과에 가까워진다" 이다.
즉, 보통 평균에 가까울수록 빈도가 높고, 평균에서 멀어질수록 빈도가 낮다!
참고로, 보통 정규분포 상 2시그마 이상 떨어져 있으면 통계적으로 유의미하다고 본다.
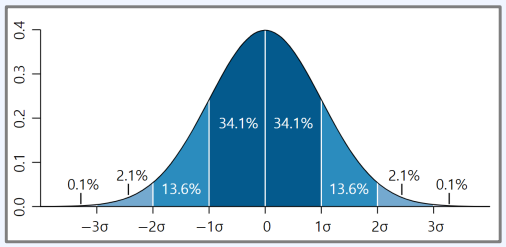
이를 바탕으로 유의성 검정의 원리는 아래와 같은 사고과정을 거친다.
1) 내 주장
2) 내 주장이 틀렸다고 해보자 (if not),
3) 그럼 지금 우리가 모은 이 데이터가 말이 된다고 생각해? 합리적이라고 생각해?
내 주장이 틀렸다는 가설 하에(if not), 수집한 데이터가 발생할 확률을 유의확률 (p-value)이라고 한다. 유의확률이 낮다는 것은 '가설이 틀렸을 확률이 낮다', 즉 내 주장이 맞을 확률이 높다는 것을 의미한다. 검증 전, 어느 정도를 기준으로 가설이 맞다/틀리다를 결정할 것인지 기준을 세운다. 이 기준을 ‘유의수준'이라 한다. 절대적이지는 않지만 보통 p-value 를 0.05 로 잡는다.
말로 풀면 상당히 헷갈리는 개념이다. 그래서 아래와 같이 도식화 해보았다.
p-value가 유의 수준보다 낮으면 가설이 틀렸다 > 내 주장이 맞다
p-value가 유의 수준보다 높으면 가설이 맞다 > 내 주장이 틀렸다

다양한 검정법의 이해
변수의 성격에 따라 검증하는 방법이 달라진다. 변수는 아래와 같이 구분될 수 있다.

통계적 검정 실습
통계적 검정 실습 예시로 과수원 사례를 들고 왔다. 상황과 가설을 정한 뒤, 기준 값과 표본 데이터로 정규성 검정, 검정 통계량, P-value 값을 추출해보았다.
# A 과수원에서 생산된 사과의 평균 무게는 200g
# 도매업자가 몇개 사과를 임의로 골라 무게를 재서 실제로 평균 무게가 200g이 될 수 있을 지 검증 하고 싶다.
# 과수원에서 생산되는 사과 15개를 임의로 뽑아서 무게를 측정
# 해당 데이터가 200g 과 유의미한 차이가 있는지 검정해보자
# 귀무가설: A 과수원에서 생산되는 사과무게의 평균값은 200g 과 다르다.
#기준값
mu = 200
#수집된 표본
data = [200, 210, 180, 190, 185, 170, 180, 180, 210, 180, 183, 191, 204, 201, 186]
import numpy as np
from scipy.stats import shapiro
statistic, p_val = shapiro(data)
# 1. 사전 점검 : 정규성을 따르는가? p_value 가 0.05 보다 크면 정규성을 충족
# 테스트와 별개로 표본의 개수가 30개를 넘어가면 정규성을 충족한다고 가정할 수 있음
print("정규성 검정")
print("검정통계량: ", statistic)
print("P-value : ", p_val)
# => p_value 가 0.05 보다 크므로 귀무가설 채택, 정규성을 충족
# 2. 통계 검정(일표본 t-검정) : p_value 가 0.05 보다 작으면 귀무가설 기각, 대립가설 채택
from scipy.stats import ttest_1samp
statistic, p_val = ttest_1samp(data, mu)
print("\n")
print("One Sample T-test")
print("검정통계량 : ", statistic)
print("P-value, : ", p_val)
# => p_value 가 0.05 보다 작으므로 귀무가설 기각, 사과의 무게는 평균 200g 이라고 볼 수 있음

파이썬 코딩 외에도 변수 간 유의성 관계를 쉽게 계산 할 수 있는 사이트가 있다. 생활 속 궁금한 주제로 테스트 해보면 어떨까?
<A/B 테스트 계산기>
https://ko.surveymonkey.com/mp/ab-testing-significance-calculator/
통계적 유의성에 대한 A/B 테스트 계산기 | SurveyMonkey
결과에 통계적 유의성이 있나요? 사용이 간편한 SurveyMonkey의 A/B 테스트 계산기를 이용하여 어떤 변화가 수익에 영향을 미치는지 알아보세요.
ko.surveymonkey.com
Reflection
데이터 분석 직무를 담당하시는 현업자분이 오셔서 강의를 해주셔서 그런지, 확실히 피부에 와닿는 실무적인 이야기들을 들어볼 수 있어 좋았다. 새싹 교육과정에 참여하길 잘했다 싶은 포인트로 기억 될 만큼의 가치가 있었다. A/B 테스트와 관련해서 실험 설계 단계에서 명확한 인과관계 설정을 위해 교란시키는 요인들에 대한 사전 점검의 필요성을 팀 실습을 통해 느꼈다. 상당히 다양한 변수들이 존재함을 발견했고, 추후 실험설계를 하게 된다면 인과추론에 대한 타당성을 검증하는 데 많은 노력을 기울여야겠다. 혼자 끙끙대며 고민하던 통계적 검증에 대해서도 구체적인 사례를 중심으로 실습해 볼 수 있어 이해도를 높이는데 영향을 주었다. 기존에 알고 있던 p-value 외 정규성에 대한 사정 검정이 필요함도 알 수 있었다. 이론적 지식이나 실무적 관점, 테크닉 모두 느리지만 조금씩 성장해감을 느끼며 뿌듯하게 글을 마무리 짓는다.